2.2月21日 项目:北京菜品市场数据爬取
案例参考链接:新发地-价格行情
这个网站上有34万多条470多个品类的菜品价格数据!(2022年开始至今,宝藏网站)
现,我们需要分析北京市场菜品价格变化,首先我们需要把他“爬”下来。
什么是网络爬虫?
解释
网络爬虫是一种自动化程序,设计用来浏览互联网,并收集特定网站上的信息。它们可以按照预先定义的规则在网页上抓取数据,并将其存储或进一步处理。网络爬虫通常被用于搜索引擎的建立,以及在数据挖掘、信息收集和监测等领域。它们通过HTTP或其他网络协议请求网页,并从返回的HTML中提取数据,可以是文本、图像、链接等内容。
应用领域
-
搜索引擎: 搜索引擎如谷歌、百度等利用爬虫来收集互联网上的信息,以建立其搜索索引并提供用户检索服务。
-
数据挖掘和信息提取: 公司和研究机构使用爬虫来从网页中抽取数据,用于市场调研、竞争情报、舆情分析等。
-
价格比较和产品信息收集: 零售商利用爬虫来监测竞争对手的价格变动,或者收集产品信息以更新自己的数据库。
-
新闻聚合和舆情监测: 新闻聚合网站和舆情监测机构使用爬虫来收集新闻报道和社交媒体上的信息,以便分析和汇总。
-
社交媒体分析: 爬虫可以用来收集社交媒体平台上的数据,分析用户行为、趋势和情绪,以及监测品牌声誉。
-
安全审计: 安全专家使用爬虫来检查网站的安全漏洞和配置错误,以便提供建议和修复措施。
法律风险
-
侵犯版权: 爬虫可能会抓取受版权保护的内容,如文章、图片、视频等,而未经授权使用这些内容可能构成侵犯版权行为。
-
违反服务条款: 很多网站都有使用条款或服务协议,规定了用户在使用网站内容时的限制和条件。使用爬虫抓取网站内容时,如果违反了网站的服务条款,可能会引发法律问题。
-
数据隐私: 如果爬虫抓取了包含个人信息的网页内容,可能会触犯数据保护法律。
-
反竞争行为: 如果爬虫被用于抓取竞争对手的信息,如价格、产品信息等,可能会构成反竞争行为,侵犯商业秘密或破坏市场竞争。
-
网络攻击: 如果爬虫被用于恶意目的,如DDoS(分布式拒绝服务攻击)、网络钓鱼等,将会触犯相关的网络安全法律。
现实情况中,以上法律分险基本很难避免。
尽可能遵循robots协议
robots协议
robots.txt 文件由网站管理员创建,并包含一系列指令,告诉搜索引擎爬虫哪些页面是允许访问的,哪些是禁止访问的。这些指令通常是基于路径或URL的模式匹配,例如,可以指定所有页面、特定目录、特定文件类型等。
可以参考google的**Robots.txt** 简介与指南
具体案例如下:
https://www.bilibili.com/robots.txt
https://www.zhihu.com/robots.txt
其实,这个协议(或者叫规范)没有任何强制力,也就是说防君子不防小人
补充知识:作为网站管理者如何防范网络爬虫?
-
限制频率和并发访问: 在网站服务器上设置访问速率限制,以防止爬虫对网站的过度访问,减轻服务器负载。你可以使用工具如IP限制、请求速率限制等来实现这一点。
-
使用验证码和人机验证: 在网站的登录页面或者访问频繁的页面添加验证码或其他人机验证机制,防止自动化爬虫的访问。
-
用户代理识别和封禁: 通过分析访问日志识别爬虫的用户代理标识,将恶意爬虫的 IP 地址加入封禁列表,限制其访问。
-
加密难以爬取的内容: 对于网站中的敏感信息或难以爬取的内容,可以采用加密或动态生成的方式来呈现,增加爬虫获取信息的难度。
-
定期更新安全措施: 定期更新网站的安全措施和防护机制,及时修补可能存在的漏洞,确保网站的安全性和稳定性。
以上其实没啥用,都能够绕过去。至于原因可以参考:
网页协议的设计缺陷导致了,无法完全限制爬虫
当年的设计者没想到现在的人能玩的那么花。。
简单讲讲原理
爬虫原理
让程序替你访问网页,并控制获取需要的部分
那么多编程语言,为啥用python
HTTP请求原理
本质上(最原始的情况下)网页其实就是一个共享的“文档”。随着技术的发展这个文档愈发的复杂。
有些时候网站需要用户提交一些“数据”,网站根据数据情况进行应答,方式有两种。
- GET请求:
-
GET请求用于从服务器获取数据。当用户在浏览器中输入URL、点击链接或提交表单时,通常会发起GET请求。
-
GET请求将参数附加在URL的末尾,以查询字符串的形式发送到服务器。例如:
http://example.com/search?q=keyword。 -
GET请求的参数会显示在URL中,因此不适合发送敏感信息,如密码等。
-
GET请求可以被缓存,可以被书签保存,也可以被浏览器历史记录保存。
- POST请求:
-
POST请求用于向服务器提交数据,通常用于表单提交、文件上传等场景。
-
POST请求将参数放在请求体中发送到服务器,而不是像GET请求一样放在URL中。因此,POST请求的参数不会显示在URL中,更适合发送大量或敏感信息。
-
POST请求的请求体中可以包含任意类型的数据,如表单字段、JSON数据、文件等。
-
POST请求不能被缓存,也不会保存在浏览器历史记录中。
HTTP响应码是服务器响应客户端请求时返回的一个三位数字状态码,用来表示请求的处理结果。这些状态码被分为五类,每一类代表着不同的含义:
-
1xx(信息性状态码): 这些状态码表示请求已被接收,继续处理。
-
2xx(成功状态码): 这些状态码表示请求已成功被服务器接收、理解、并接受处理。
- 200 OK: 请求成功。常用于GET和POST请求。
- 3xx(重定向状态码): 这些状态码表示需要客户端进行额外的操作才能完成请求。
-
301 Moved Permanently: 请求的资源已被永久移动到新的URL。
-
302 Found / Moved Temporarily: 请求的资源临时移动到新的URL。
- 4xx(客户端错误状态码): 这些状态码表示客户端发出的请求有错误,服务器无法处理。
-
400 Bad Request: 请求无效,语法错误等。
-
401 Unauthorized: 请求未经授权,需要进行身份验证。
-
403 Forbidden: 服务器拒绝请求,权限不足。
-
404 Not Found: 请求的资源不存在。
- 5xx(服务器错误状态码): 这些状态码表示服务器在处理请求时发生了错误。
-
500 Internal Server Error: 服务器内部错误。
-
503 Service Unavailable: 服务器当前无法处理请求,通常是临时性的故障。
通过观察HTTP响应码,可以了解到请求的处理情况,有助于诊断问题并进行相应的处理。
爬虫
根据课程我将爬虫由易到难分为以下几种:
-
无任何防护,无登录需求。将关键信息放在了json中(例如:北京新发地)
-
没有特殊防护,需要登录。将关键信息放在了json中(例如:学校学生成绩)
-
关键信息呈现在页面上,但不在json中(例如:知乎,天气历史)
-
有防护有混淆有加密,需要一定的“信息安全手段”(例如:某考试平台)
-
不断出现人机验证(B站。。。。)
-
google的人机验证(目前我没找到有效办法解决)
项目:北京菜品市场数据爬取
典型的“无登录需求。将关键信息放在了json中”(有防护,“限制频率和并发访问”)
项目需求:
爬取2022-01-01至今34万条数据。
最终形成类似如下的数据分析价格走势图(非本次内容)
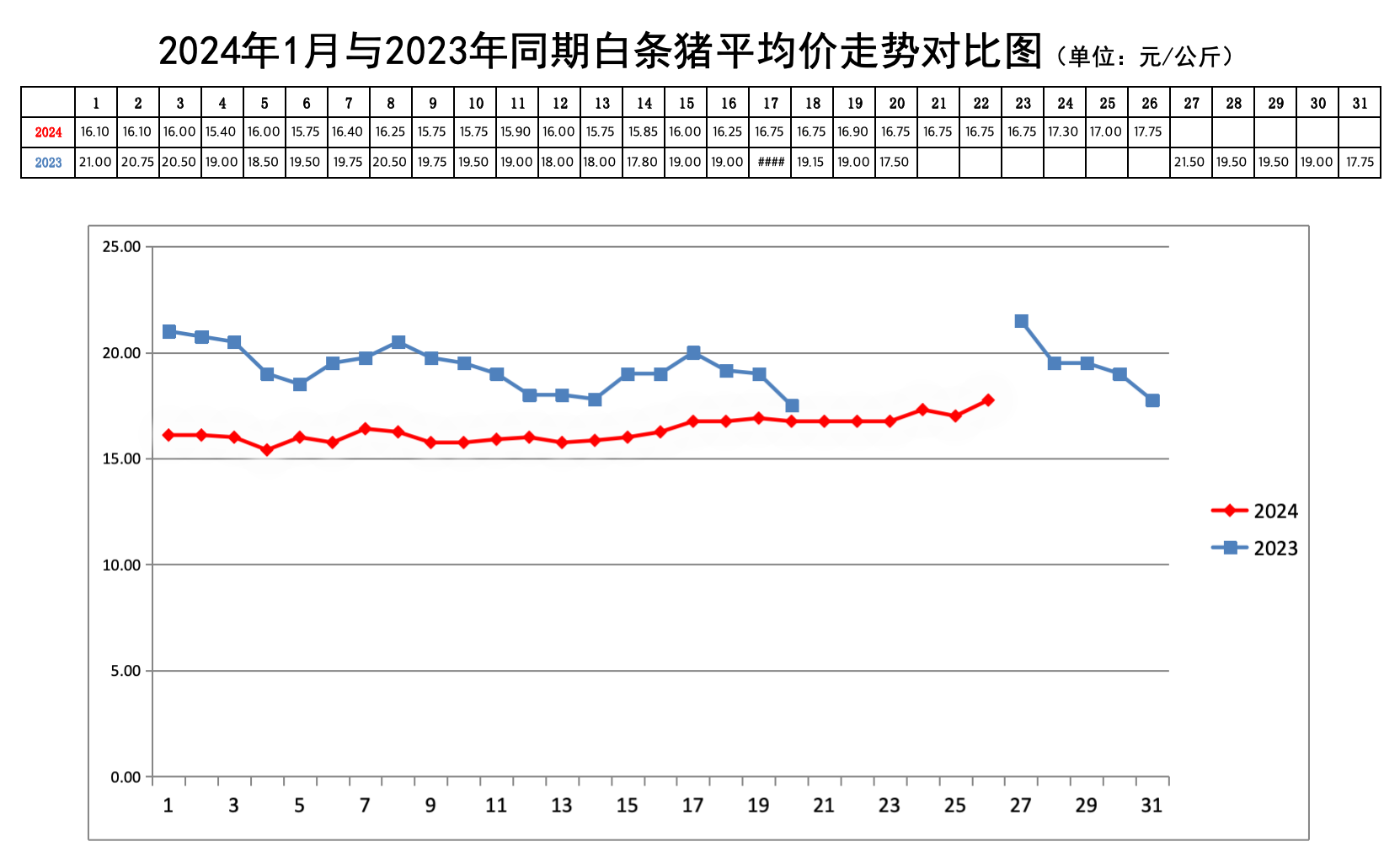
过程:
1. 安装requests库
2. 找到数据网址并验证
3. 通过AI转换为python请求
4. 验证请求
5. 根据需要修改代码进行循环爬取
最终代码:
import requests
import time
url = "http://www.xinfadi.com.cn/getPriceData.html"
headers = {
"accept": "*/*",
"accept-language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6",
"content-type": "application/x-www-form-urlencoded; charset=UTF-8",
"x-requested-with": "XMLHttpRequest",
}
i=0
while True:
i+=1
data = {
"limit": "100",
"current": str(i),
"pubDateStartTime": "",
"pubDateEndTime": "",
"prodPcatid": "",
"prodCatid": "",
"prodName": "",
}
response = requests.post(url, headers=headers, data=data)
if response.status_code == 200 :
json_data = response.json()
if len(json_data['list']) != 0:
print(json_data)
time.sleep(2)
else:
break
else:
print("出现错误啦!错误代码:", response.status_code)
break
不知之处:
从爬虫角度,不考虑数据分析和可视化,此代码主要存在以下不足:
-
获取到的没有保存!之后课程解决。
-
效率低下。。(只讲思路,可以解决但本课程不打算解决,因为难)
