6. 9月25日 泰坦尼克号生还预测1-数据预处理
6. 9月25日 泰坦尼克号生还预测1-数据预处理
项目背景
泰坦尼克号(Titanic),又称铁达尼号,是当时世界上体积最庞大、内部设施最豪华的客运轮船,有“永不沉没”的美誉,被称为“世界工业史上的奇迹”。1912年4月10日,她在从英国南安普敦出发,驶往美国纽约的首次处女航行中,不幸与一座冰山相撞,1912年4月15日凌晨2时20分左右,船体断裂成两截,永久沉入大西洋底3700米处,2224名船员及乘客中,逾1500人丧生。
而以此事件为背景的《泰坦尼克号》则是成为了电影史上的传奇,该片由詹姆斯•卡梅隆执导,莱昂纳多•迪卡普里奥、凯特•温斯莱特领衔主演。
机器学习领域,著名的数据科学竞赛平台kaggle的入门经典也是以泰坦尼克号事件为背景。该问题通过训练数据(train.csv)给出891名乘客的基本信息以及生还情况,通过训练数据生成合适的模型,并根据另外418名乘客的基本信息(test.csv)预测其生还情况,并将生还情况以要求的格式(gender_submission.csv)提交,kaggle会根据你的提交情况给出评分与排名。
Kaggle 介绍
Kaggle是一个专注于数据科学和机器学习竞赛的在线平台,由Anthony Goldbloom于2010年在墨尔本创立,并在2017年被Google收购。它为数据科学家和机器学习工程师提供了一个展示技能、参与竞赛和项目、分享和发现数据集以及建立和参与数据科学团队的空间。
Kaggle拥有庞大的数据集库,这些数据集对所有用户免费开放,并且经常在竞赛中使用。
对于新手来说,Kaggle提供了入门级别的竞赛,这些竞赛适合初学者练习和学习数据科学技能,虽然没有奖金,但提供了宝贵的实践经验。Kaggle还鼓励用户组队参赛,共享代码和数据集,相互提供反馈,促进学习和合作。
数据集介绍
项目共提供三个数据集:
- 训练集(train.csv)
- 测试集(test.csv)
- 提交文件示例(gender_submission.csv)
train.csv文件作为训练集,包含人员编号,人员信息,最终生存情况
test.csv文件则用作测试集,包含人员编号,人员信息,不包含最终生存情况
gender_submission.csv文件为提交文件示例,交给kaggle平台进行评分。
人员信息数据说明
| PassengerId | 乘客ID |
|---|---|
| Survived | 是否获救,1为是,0为否 |
| Pclass | 乘客票务舱,1表示最高级,还有2、3等级的 |
| Name | 乘客姓名 |
| Sex | 性别 |
| Age | 年龄 |
| SibSp | 堂兄弟妹个数 |
| Parch | 父母与小孩个数 |
| Ticket | 船票号 |
| Fare | 票价 |
| Cabin | 客舱号 |
| Embarked | 登船港口 |
机器学习
机器学习是人工智能的一个分支,它使计算机系统能够从数据中学习并做出决策,而无需进行明确的编程。机器学习主要分为三种类型:监督学习、无监督学习和强化学习。
任务分类
分类 (Classification)
- 定义:分类是监督学习中的一种任务,目的是预测离散的标签。
- 目标:确定一个实例属于哪个类别。
- 应用示例:垃圾邮件检测(垃圾邮件/非垃圾邮件)、疾病诊断(良性/恶性)。
- 常见算法:逻辑回归、支持向量机(SVM)、决策树、随机森林、神经网络。
回归 (Regression)
- 定义:回归也是监督学习的一种任务,目的是预测连续的数值。
- 目标:预测一个实例的数值型输出。
- 应用示例:房价预测、股票价格走势、气温变化。
- 常见算法:线性回归、岭回归、支持向量回归(SVR)、决策树回归。
聚类 (Clustering)
- 定义:聚类是无监督学习的一种任务,目的是将数据点分成若干组。
- 目标:使组内的数据点尽可能相似,组间的数据点尽可能不同。
- 应用示例:市场细分、社交网络分析、图像分割。
- 常见算法:K-Means、层次聚类(Hierarchical Clustering)、DBSCAN。
降维 (Dimensionality Reduction)
- 定义:降维是另一种无监督学习任务,旨在减少数据的维度,同时保留重要信息。
- 目标:简化数据的复杂性,去除噪声和冗余信息,提高数据处理的效率。
- 应用示例:数据可视化、提高算法性能、发现数据的潜在结构。
- 常见算法:主成分分析(PCA)、线性判别分析(LDA)、t-SNE。
学习方式
监督学习、无监督学习和强化学习是机器学习中的三种主要学习范式,它们在目标、方法和应用场景上有显著的区别:
监督学习 (Supervised Learning)
监督学习是一种机器学习任务,其中模型从标记的训练数据中学习,每个训练样本都包含输入特征和相应的输出标签。模型的目标是学习出一个映射规则,使其能够根据新的输入预测输出。监督学习通常用于分类和回归任务。
- 目标:利用有标签的数据集来训练模型,使其能够预测未见过数据的输出标签。
- 方法:通过喂给模型输入特征和对应的输出标签来学习一个映射函数。
- 类型:主要包括分类(Classification)和回归(Regression)问题。
- 评估:使用准确率、召回率、F1分数、均方误差等指标来评估模型性能。
- 应用:图像识别、语音识别、股票价格预测等。
无监督学习 (Unsupervised Learning)
无监督学习是一种机器学习任务,其中模型在没有标签的数据集上进行学习。无监督学习的目标是发现数据中的结构和模式。无监督学习通常用于聚类和关联规则学习任务。
- 目标:在没有标签的数据集上发现数据的内在结构和模式。
- 方法:尝试理解数据的分布和关系,如聚类和密度估计。
- 类型:主要包括聚类(Clustering)和降维(Dimensionality Reduction)。
- 评估:通常更主观,可能包括聚类的质量或降维后的重构误差。
- 应用:市场细分、社交网络分析、异常检测等。
强化学习 (Reinforcement Learning)
强化学习(Reinforcement Learning,RL)是机器学习的一个重要分支,它通过智能体(Agent)与环境(Environment)的交互来学习最优行为策略。强化学习的核心是智能体在尝试过程中,根据环境给予的奖励(Reward)来学习如何在特定环境中实现目标。它不依赖于预先标注好的数据集,而是通过试错、探索和利用来学习策略。
目标:训练一个智能体(Agent)在环境中通过试错来学习最优行为策略,以最大化累积奖励。方法:智能体与环境交互,根据奖励信号来学习在不同状态下应采取的动作。类型:通常分为基于价值的方法(如Q学习)和基于策略的方法(如策略梯度)。评估:通过智能体在环境中的表现和获得的累积奖励来评估。应用:游戏AI、自动驾驶、机器人控制、资源管理等。
主要区别
- 数据标签:
- 监督学习需要有标签的数据。
- 无监督学习使用无标签的数据。
- 强化学习不依赖于外部标签,而是依赖于环境的奖励信号。
- 目标和反馈:
- 监督学习的目标是基于输入预测输出标签。
- 无监督学习的目标是发现数据的内在结构。
- 强化学习的目标是在给定环境中通过试错来学习最优策略。
- 学习过程:
- 监督学习是被动的,模型仅从数据中学习。
- 无监督学习也是被动的,模型试图理解数据的结构。
- 强化学习是主动的,智能体通过与环境的交互来学习。
- 应用场景:
- 监督学习适用于有明确输出标签的问题。
- 无监督学习适用于探索数据结构和模式的问题。
- 强化学习适用于需要决策和优化策略的问题。
环境准备
1. Anaconda
略
2. 创建新的虚拟环境
略
创建新的虚拟环境kaggle
conda create -n kaggle python=3.10
COBOL
激活kaggle环境
conda activate kaggle
3. 安装相应库
安装sklearn库scikit-learn中文社区
Scikit-learn(简称sklearn)是一个开源的机器学习库,用于Python编程语言。它建于SciPy库之上,与NumPy、Pandas等数据处理库兼容,是Python数据科学生态系统中的重要组成部分。Scikit-learn由David Cournapeau在2007年发起,目的是提供一个简单高效的工具,用于数据挖掘和数据分析。
以下是Scikit-learn的一些关键特点:
- 算法丰富:Scikit-learn提供了各种机器学习算法,包括但不限于:
- 线性回归、逻辑回归
- 支持向量机(SVM)
- 决策树、随机森林、梯度提升树
- 聚类算法(如K-Means、层次聚类)
- 降维算法(如PCA、t-SNE)
- 邻居算法(如K-最近邻、半径邻居)
- 神经网络
- 数据预处理:Scikit-learn提供了数据预处理功能,包括标准化、归一化、编码类别特征等。
- 模型选择和评估:Scikit-learn包含了模型选择和评估工具,如交叉验证、网格搜索、性能度量等。
- 兼容性:Scikit-learn与Python的数据操作库(如Pandas)和数据可视化库(如Matplotlib、Seaborn)兼容。
主要功能见图:

Scikit-learn适用于从简单的机器学习任务到复杂的预测分析,是数据科学家和机器学习工程师常用的工具之一。
conda install scikit-learn
pip install pandas -i https://pypi.tuna.tsinghua.edu.cn/simple/
pip install matplotlib -i https://pypi.tuna.tsinghua.edu.cn/simple/
本次课程需要用到的库包括:
- sklearn
- pandas
- numpy
- matplotlib
- seaborn
- 等
数据预处理
导入数据
vscode中选择kaggle环境
import pandas as pd
train_file = r'data/train.csv'
train_data = pd.read_csv(train_file)
print(train_data.head())
娴熟数据前5行,和excel显示一样

数据特征初步分析
显示统计分析
print(train_data.describe())
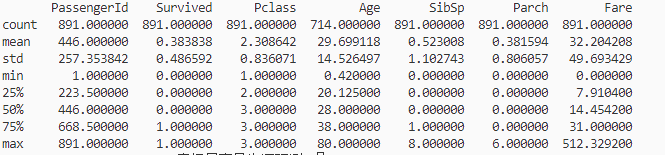
统计摘要
- count:每个字段的观测值数量。例如,所有891个乘客都有
PassengerId和Survived的数据,但Age数据缺失了177个(891-714)。 - mean:每个字段的平均值。例如,
Age的平均值约为29.699岁。 - std:每个字段的标准差,表示数据的离散程度。
- min:每个字段的最小值。
- 25%:每个字段的第一四分位数,表示至少有25%的观测值小于或等于这个值。例如,
Age的25%分位数是20.125岁。 - 50%(中位数):每个字段的中位数,表示所有观测值的中间值。例如,
Age的中位数是28岁。 - 75%:每个字段的第三四分位数,表示至少有75%的观测值小于或等于这个值。例如,
Age的75%分位数是38岁。 - max:每个字段的最大值。例如,
Age的最大值是80岁。
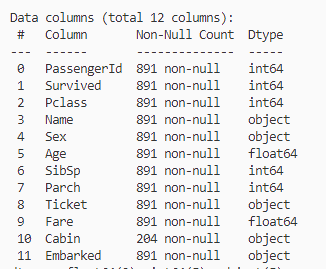
print(train_data.info())
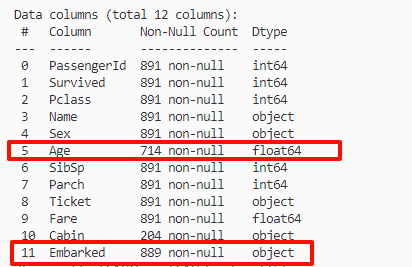
age,Embarked 缺失值需要进行填充
缺失值填充
年龄缺失值可以使用中位数进行填充
# 用中值填补缺失值
train_data['Age'] = train_data['Age'].fillna(train_data['Age'].median())
print(train_data.describe())
这行代码的作用是将 train数据集中 Age列的缺失值用该列的中值(median)来填补。在Python的Pandas库中,.fillna()函数用于填充DataFrame或Series中的缺失值(NaN)。
train['Age'].median()计算Age列的中值。中值是将数据集从小到大排序后位于中间的值,如果数据集有偶数个观测值,则中值是中间两个数的平均值。train['Age'].fillna(...)将Age列中的所有NaN值替换为计算出的中值
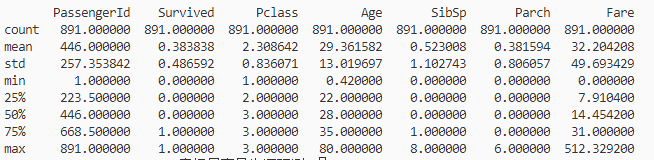
Embarked也有缺失,统一用S进行填充
train_data['Embarked'] = train_data['Embarked'].fillna('S')
print(train_data.info())
数据转化
print(train_data.info())
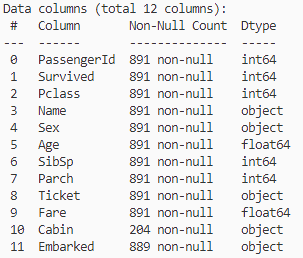
例如:SEX 性别,类似是object 实际是male,female.
机器学习不能很好的处理字符形式的数据,我们需要将数据进行转换
例如将male转换为0,female.转换为1
train_data.loc[train_data['Sex'] == 'male', 'Sex'] = 0
train_data.loc[train_data['Sex'] == 'female', 'Sex'] = 1
print(train_data.head())

同理处理Embarked(登船地点),S=0,C=1,Q=2
train_data.loc[train_data['Sex'] == 'male', 'Sex'] = 0
train_data.loc[train_data['Sex'] == 'female', 'Sex'] = 1
train_data.loc[train_data['Embarked'] == 'S', 'Embarked'] = 0
train_data.loc[train_data['Embarked'] == 'C', 'Embarked'] = 1
train_data.loc[train_data['Embarked'] == 'Q', 'Embarked'] = 2
print(train_data.head())

特征工程
特征工程(Feature Engineering)极其重要,特征的选择与处理直接影响到模型效果。实际中,特征工程很多时候是依赖业务经验的。
通过数据探查,可以发现该数据包含以下几类属性
- 标称属性(Nominal attribute):Sex(性别)、Embarked(登船港口)、Pclass(客舱等级)
- 数值属性(Numeric attribute):Age(年龄)、SibSp(兄弟姐妹、配偶)、Parch(父母与子女)、Fare(票价)
- 其他:Name(乘客姓名)、Ticket(船票编号)、Cabin(客舱号)
统计分析性别、客舱等级、上船点与生还结果的相关性
引入库
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文字体为黑体
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
计划画三张图:
- 不同性别的生还情况
- 不同客舱等级生还情况
- 不同上船点生还情况
创建一个新的图形对象
fig = plt.figure()
这行代码创建了一个新的 figure对象
设置图形的透明度
fig.set(alpha=0.65)
这行代码设置了整个图形的透明度。alpha参数的值范围从0.0(完全透明)到1.0(完全不透明)。在这里,设置为0.65意味着图形的透明度为65%。
添加子图
ax1 = fig.add_subplot(131)
ax2 = fig.add_subplot(132)
ax3 = fig.add_subplot(133)
这些行代码在图形对象上添加了三个子图。add_subplot()方法用于在图形上添加子图(即图表中的小图)。
131、132和133是子图的布局代码,它们指定了子图的排列方式。这里的数字表示:- 第一个数字(1)表示图形被分成一行。
- 第二个数字(3)表示图形被分成三列。
- 组合起来,
131、132和133分别表示第一行第一列、第一行第二列和第一行第三列的子图。
创建性别与生存率的交叉表并归一化
cou_Sex = pd.crosstab(train_data.Sex,train_data.Survived)
cou_Sex.rename({0:'未生还',1:'生还'},axis=1,inplace=True)
cou_Sex.rename({1:'女',0:'男'},inplace=True)
pct_Sex = cou_Sex.div(cou_Sex.sum(1).astype(float),axis=0) #归一化
pct_Sex.plot(kind='bar', stacked=True, title=u'不同性别的生还情况', ax=ax1)
cou_Sex = pd.crosstab(train_data.Sex, train_data.Survived)
pd.crosstab函数用于创建一个交叉表,这是一种用于显示两个(或更多)变量之间关系的表格。在这里,它显示了 train_data数据集中 Sex(性别)和 Survived(生存状态)之间的关系。

cou_Sex.rename({0:'未生还', 1:'生还'}, axis=1, inplace=True)
这行代码将交叉表的列名从数字(0和1)重命名为中文描述('未生还'和'生还')
cou_Sex.rename({1:'女', 0:'男'}, inplace=True)
这行代码将交叉表的行名从数字(0和1)重命名为中文描述('男'和'女')
pct_Sex = cou_Sex.div(cou_Sex.sum(1).astype(float), axis=0)
这行代码将交叉表中的数据进行归一化处理,使得每一行的值相加等于1。这是通过将每个值除以其所在行的总和来实现的。cou_Sex.sum(1)计算每一行的总和,astype(float)确保计算时使用浮点数以避免整数除法。axis=0表示操作是沿着列进行的,即每一行的值都被其行总和所除。
pct_Sex.plot(kind='bar', stacked=True, title=u'不同性别的生还情况', ax=ax1)
在第一个子图上绘制归一化数据的堆叠条形图,显示不同性别的生还情况。
创建船舱等级与生存率的交叉表并归一化
cou_Pclass = pd.crosstab(train_data.Pclass, train_data.Survived)
cou_Pclass.rename({0:'未生还', 1:'生还'}, axis=1, inplace=True)
pct_Pclass = cou_Pclass.div(cou_Pclass.sum(1).astype(float), axis=0)
pct_Pclass.plot(kind='bar', stacked=True, title=u'不同等级的生还情况', ax=ax2, sharey=ax1)
略
创建登船港口与生存率的交叉表并归一化
cou_Embarked = pd.crosstab(train_data.Embarked,train_data.Survived)
cou_Embarked.rename({0:'未生还',1:'生还'},axis=1,inplace=True)
cou_Embarked.rename({0:'S',1:'C',2:'Q'},inplace=True)
pct_Embarked = cou_Embarked.div(cou_Embarked.sum(1).astype(float),axis=0)
pct_Embarked.plot(kind='bar',stacked=True,title=u'不同登录点生还情况',ax=ax3,sharey=ax1)
略
显示图形
fig.show()
显示整个图形对象。
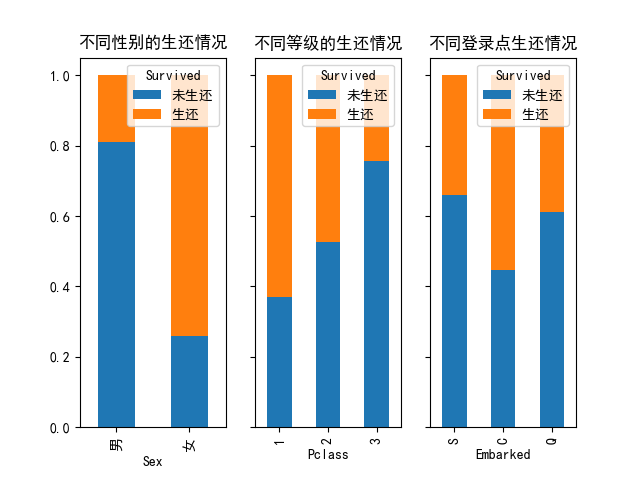
可直观的看出生还情况受性别(女性乘客生还概率较高)、客舱等级(一等舱乘客生还概率较高)、登船港口(C港口登船乘客生还概率较高,玄学!)的影响。
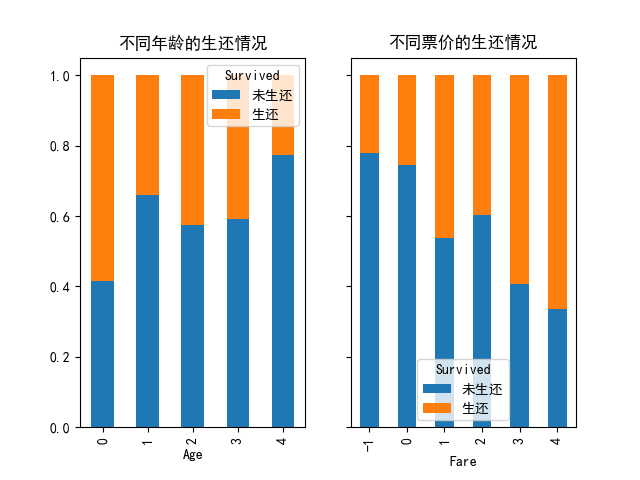
统计分析年龄、票价与生还结果的相关性
这部分复杂,略
只看结果
fig = plt.figure()
fig.set(alpha=0.65) # 设置图像透明度
ax1 = fig.add_subplot(121)
ax2 = fig.add_subplot(122)
bins = [0, 14, 30, 45, 60, 80]
# Age离散化
cats = pd.cut(train_data['Age'], bins) # 使用pd.cut直接对Series操作
train_data['Age'] = cats.cat.codes
cou_Age = pd.crosstab(train_data['Age'], train_data['Survived'])
cou_Age.rename({0: '未生还', 1: '生还'}, axis=1, inplace=True)
pct_Age = cou_Age.div(cou_Age.sum(1).astype(float), axis=0)
pct_Age.plot(kind='bar', stacked=True, title=u'不同年龄的生还情况', ax=ax1)
bins = [0, 15, 30, 45, 60, 300]
# Fare离散化
cats = pd.cut(train_data['Fare'], bins) # 使用pd.cut直接对Series操作
train_data['Fare'] = cats.cat.codes
cou_Fare = pd.crosstab(train_data['Fare'], train_data['Survived'])
cou_Fare.rename({0: '未生还', 1: '生还'}, axis=1, inplace=True)
pct_Fare = cou_Fare.div(cou_Fare.sum(1).astype(float), axis=0)
pct_Fare.plot(kind='bar', stacked=True, title=u'不同票价的生还情况', ax=ax2, sharey=ax1)
plt.show()