33.5月20日 项目:对招聘数据进行分析和可视化处理-工资数据
项目:对招聘数据进行分析和可视化处理-工资数据
目标是在上节课爬虫基础上,利用爬取的csv格式文件中的数据进行工资数据分析。
效果图:

附加:饼图呈现“岗位所在行业(前10)”

步骤一:导入必要的库
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
这些库用于数据处理和可视化:
- pandas 用于数据读取和处理。
- matplotlib 和 seaborn 用于绘制图表。
- numpy 用于数值计算。
步骤二:读取CSV文件
文件名称根据实际情况进行修改
df = pd.read_csv('爬虫岗位招聘信息.csv')
读取包含爬虫岗位招聘信息的CSV文件,存储在DataFrame df 中。
csv数据内容如下:

步骤三:将薪资转换为数值型并计算月薪
原先数据为年薪数据,为能直观展现数据,需要将年薪转换为月薪
df['薪资'] = df['薪资'].astype(int)
df['月薪'] = df['薪资'] / 12

创建薪资区间并计算每个区间的频数
即使统计完月薪数据,但月薪仍旧处于“离散”状态。我们需要通过区间将离散的月薪进行归类。
bins = np.arange(3000, df['月薪'].max() , 1000)
df['薪资区间'] = pd.cut(df['月薪'], bins)
salary_counts = df['薪资区间'].value_counts().sort_index()
bins变量为薪资区间,使用np生成等差数列,最小为3000,每次增加1000,最大到工资最大值。
使用 pd.cut 将月薪数据分配到这些区间中。其中:
- df['薪资区间']: 这是一个新的列名,我们将使用它来存储每个月薪所属的区间。
- pd.cut(): 这是pandas的一个函数,用于将数据划分成离散的区间。
- df['月薪']: 这是我们想要分割的数据列,即月薪数据。
salary_counts = df['薪资区间'].value_counts().sort_index()作用是计算每个区间的频数,并按区间排序。
- df['薪资区间']: 这是之前通过pd.cut()函数创建的新列,其中存储了每个月薪所属的区间。
- .value_counts(): 这是一个 pandas 函数,用于计算每个唯一值出现的频数。在这里,它会计算每个区间出现的次数,也就是每个区间内有多少个月薪数据点。
- .sort_index(): 这个方法用于对结果进行排序,因为value_counts()默认是按照频数进行排序,但在这里我们想要按照区间的顺序进行排序,所以使用了sort_index()来实现这一点。

过滤频数较少的区间
如上图,会发现实际操作中会出现一些频数非常少的空间。
这些在统计中是没有意义的。需要进行过滤。
threshold = 3 # 设定阈值,去除频数小于3的区间
filtered_salary_counts = salary_counts[salary_counts > threshold]
绘制折线图
设置字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
绘制图
plt.figure(figsize=(12, 8))
plt.plot(filtered_salary_counts.index.astype(str), filtered_salary_counts.values)
plt.title('月薪分布', fontsize=16)
plt.xlabel('月薪区间(元)', fontsize=14)
plt.ylabel('岗位数量', fontsize=14)
plt.xticks( fontsize=12)
plt.yticks(fontsize=12)
plt.grid(True)
plt.show()
其中关键语句为 plt.plot(filtered_salary_counts.index.astype(str), filtered_salary_counts.values)
filtered_salary_counts.index.astype(str)内容为filtered_salary_counts这个df的index也就是区间名称
filtered_salary_counts.values内容为filtered_salary_counts这个df的value也就是频数
图解如下:

完成效果如下:

问题主要在X轴标签内容,由于显示的是df的index,内容既不合适也太长。我们需要对其进行处理。
修改X轴标签
# 自定义设置X轴刻度
custom_xticks = []
for interval in filtered_salary_counts.index:
left_value = int(interval.left) // 1000 # 左边界值(取整并转换为千)
right_value = int(interval.right) // 1000 # 右边界值(取整并转换为千)
label = '{}k-{}k'.format(left_value, right_value) # 构建标签
custom_xticks.append(label)
plt.xticks(filtered_salary_counts.index.astype(str), custom_xticks, fontsize=12)
重点解释:
label = '{}k-{}k'.format(left_value, right_value)
- {} 是一个占位符,用来表示后续 format() 方法中的变量会填充的位置。
- format(left_value, right_value) 是 format() 方法的调用,它会将 left_value 和 right_value 的值填充到字符串中的相应位置。
- left_value 和 right_value 分别代表区间的左边界值和右边界值。
- '{}k-{}k' 是一个包含了两个占位符的字符串,其中 k 是表示千的单位。
假设 left_value 的值是 3,right_value 的值是 5,那么 format() 方法就会将这两个值填充到字符串中的占位符位置上,得到的 label 就是 '3k-5k'。
plt.xticks(filtered_salary_counts.index.astype(str), custom_xticks, fontsize=12)
这行代码是用来设置X轴的刻度标签的
- filtered_salary_counts.index.astype(str): 这部分是指定X轴刻度的位置。
- custom_xticks: 这是指定X轴刻度的标签文本。在这里,custom_xticks 是一个列表,包含了我们自定义生成的刻度标签文本。每个标签文本代表一个区间的范围。
结果

import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
# 设置字体和负号显示
plt.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
# 读取CSV文件
df = pd.read_csv('爬虫岗位招聘信息.csv')
# 将薪资转换为数值型(假设薪资单位是元)
df['薪资'] = df['薪资'].astype(int)
df['月薪'] = df['薪资'] / 12
print(df['月薪'] )
# 创建薪资区间并计算每个区间的频数
bins = np.arange(3000, df['月薪'].max(), 1000)
df['薪资区间'] = pd.cut(df['月薪'], bins)
salary_counts = df['薪资区间'].value_counts().sort_index()
# 设置阈值,去除频数较少的区间
threshold = 3 # 例如,频数小于3的区间将被去除
filtered_salary_counts = salary_counts[salary_counts > threshold]
print(salary_counts)
# 绘制折线图
plt.figure(figsize=(12, 8))
plt.plot(filtered_salary_counts.index.astype(str), filtered_salary_counts.values)
plt.title('月薪分布', fontsize=16)
plt.xlabel('月薪区间(元)', fontsize=14)
plt.ylabel('岗位数量', fontsize=14)
# 自定义设置X轴刻度
custom_xticks = []
for interval in filtered_salary_counts.index:
left_value = int(interval.left) // 1000 # 左边界值(取整并转换为千)
right_value = int(interval.right) // 1000 # 右边界值(取整并转换为千)
label = '{}k-{}k'.format(left_value, right_value) # 构建标签
custom_xticks.append(label)
plt.xticks(filtered_salary_counts.index.astype(str), custom_xticks, fontsize=12)
plt.yticks(fontsize=12)
plt.grid(True)
plt.show()
附加:饼图呈现“岗位所在行业(前10)”
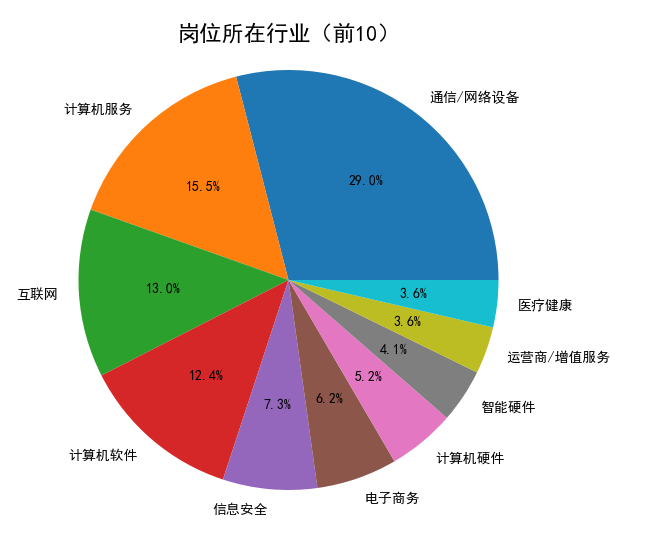
industry_demand = df['行业'].value_counts().head(10)
# 绘制饼图
plt.figure(figsize=(10, 6))
plt.pie(industry_demand.values, labels=industry_demand.index, autopct='%1.1f%%', )
plt.title('岗位所在行业(前10)', fontsize=16)
# 显示图形
plt.axis('equal') # 使饼图比例相等,呈现圆形
plt.show()
plt.pie() 参数解释:
- x:用于绘制饼图的数据,通常是一个数组或 Series。
- labels:用于指定每个扇形部分的标签,通常是一个包含字符串的列表或数组,与数据 x 的长度相同。
- autopct:可选参数,用于控制显示在每个扇形部分中的百分比格式。'%1.1f%%' 表示显示小数点后一位的百分比格式。
在这个特定的 plt.pie() 调用中,industry_demand.values 是岗位数量数据,industry_demand.index 是行业标签,autopct='%1.1f%%' 用于显示百分比。
