27.4月29日 项目: selenium库实现爬虫,爬B站
selenium库
Selenium是一个用于Web应用程序测试的工具。Selenium测试可以运行在多种浏览器上,包括但不限于Chrome、Firefox、Safari和Internet Explorer。
注意:selenium 库原本设计是应用在网页测试上的。
当下,各种网站的反爬虫手段愈发高明。爬虫愈发困难。
但是Selenium 由于完全模仿用户实际操作,故可以处理一些常规爬虫库(如requests、BeautifulSoup等)难以应对的场景。
但是效率略微有点低。主要是速度慢。
安装selenium 库
下载库:pip install -i https://pypi.tuna.tsinghua.edu.cn/simple selenium
这个库比较大。其实在安装 selenium库的时候,同时安装了msedgedriver.exe
这是个浏览器驱动,我们可以简单的将他理解成selenium通过这个程序实现控制我们浏览器的作用。
注意:如果安装出现问题,导致msedgedriver.exe没有安装的话后续功能是无法实现的。
项目:简单测试-使用selenium库打开B站并获取信息
引入库
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
from selenium import webdriver
- 这行代码从
selenium模块中导入了webdriver。webdriver是Selenium的核心组件,它提供了一个简单的API来控制Web浏览器。通过webdriver,你可以编写代码来模拟用户的各种操作,如打开网页、点击按钮、填写表单、获取页面内容等。
from selenium.webdriver.common.by import By
这行代码从selenium.webdriver.common.by模块中导入了By类。By类提供了一组静态方法,这些方法用于在Web页面上定位元素。在Selenium中,定位元素是执行任何操作的前提,因为所有的操作都是针对页面上的特定元素进行的。
By类中定义了几种常用的定位元素的方法,包括:
By.ID: 通过元素的ID属性来定位。By.XPATH: 使用XPath表达式来定位元素。(重点!!)By.CSS_SELECTOR: 使用CSS选择器来定位元素。By.NAME: 通过元素的NAME属性来定位。By.TAG_NAME: 通过元素的标签名来定位。By.CLASS_NAME: 通过元素的类名来定位。By.LINK_TEXT: 通过链接的完整文本来定位链接元素。By.PARTIAL_LINK_TEXT: 通过链接文本的部分内容来定位链接元素。
打开测试网页
# 打开浏览器(独立环境)
browser = webdriver.Edge()
# 网页最大化
browser.maximize_window()
browser.get('https://www.bilibili.com/')
# 停留200秒,再结束程序
time.sleep(200)
打开热门排行
![[Pasted image 20240428183451.png]](/upload/Pasted%20image%2020240428183451.png)
找到元素
这里就要用到selenium.webdriver.common.by模块的功能了,虽然可以通过多种方式获取网页的元素。
但我只推荐一种方式XPATH!
![[Pasted image 20240428184134.png]](/upload/Pasted%20image%2020240428192934.png)
popular = browser.find_element(By.XPATH, '//*[@id="i_cecream"]/div[2]/div[1]/div[3]/div[1]/a[2]')
popular对象就是获取到的网页上的这个元素。
实现点击
popular.click()
这个等待必不可少,为了等待网页加载完成。
否则后续的元素可能是获取不到的。有时候需要根据网络情况调大这个等待值。
切换标签页
运行程序发现,当点击后,打开了新的标签页
这时候,如果不进行处理,后续代码还是在原先的标签页中运行的。
需要切换标签页!
handles = browser.window_handles
browser.switch_to.window(handles[-1])
在Selenium中,handles 和 switch_to.window 是用来处理浏览器标签页(windows)和上下文(contexts)的两个重要的概念。
browser.window_handles这是一个属性,它返回当前浏览器实例中打开的所有标签页的句柄(handles)的列表。每个标签页都有一个唯一的句柄,可以认为是标签页的标识符。
handles = browser.window_handles
在这行代码中,handles 将包含一个字符串列表,每个字符串都是一个标签页的句柄。
例如,如果有三个标签页打开,handles 可能看起来像这样:
['CDA6C31B', 'CA0AB3FB', 'CBC34A23']
browser.switch_to.window()这是一个方法,它允许您在Selenium WebDriver中切换到不同的标签页上下文。当您调用 switch_to.window() 方法时,您需要提供一个标签页的句柄作为参数,这样Selenium就知道您想要在哪个标签页上执行后续的操作。
browser.switch_to.window(handles[-1])
在这行代码中,handles[-1] 引用了句柄列表中的最后一个元素,它代表了最近打开的标签页。调用 switch_to.window(handles[-1]) 会让Selenium切换到这个最新的标签页,之后的命令都会在这个标签页上执行,直到您再次切换上下文。
热门视频的名称
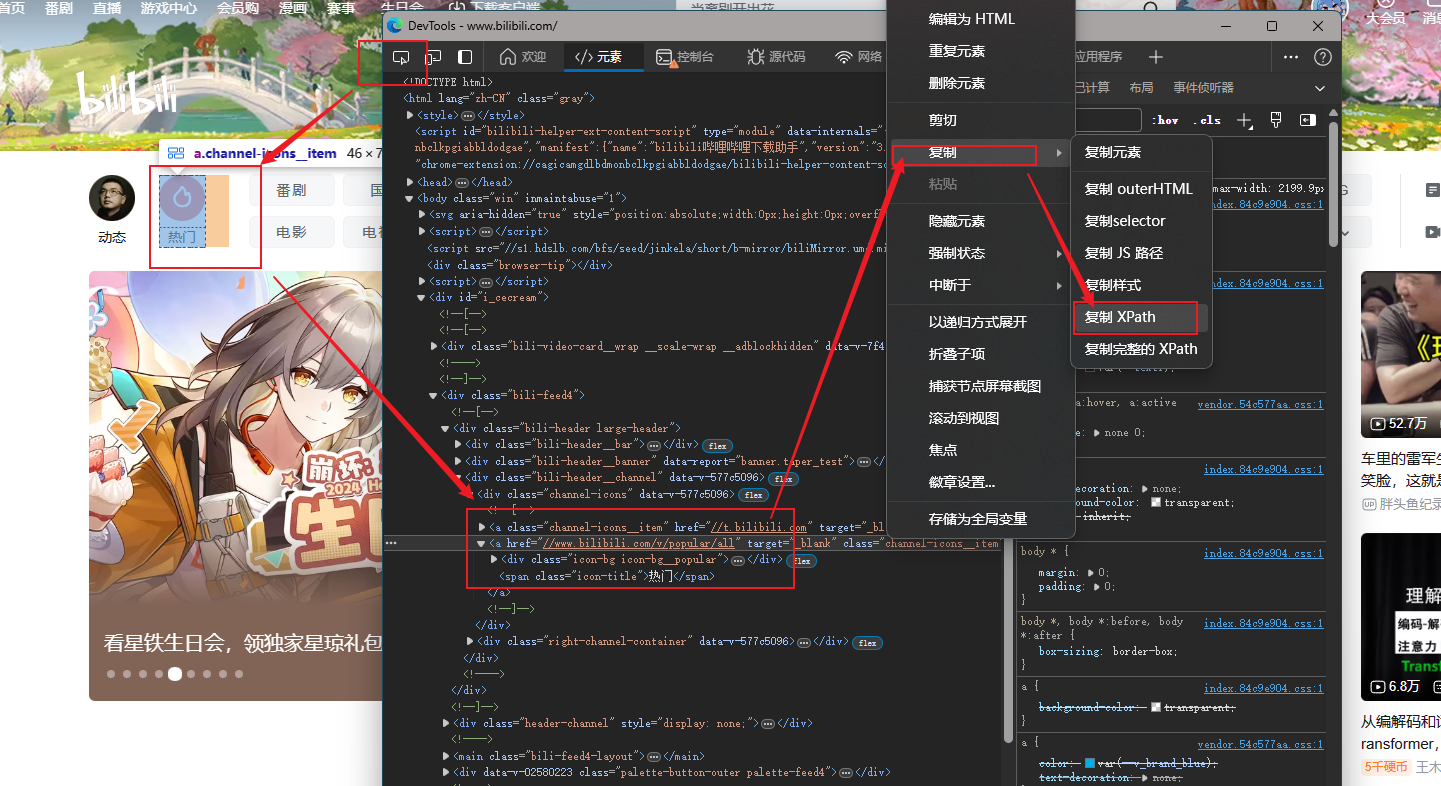
获取热门视频的XPath
得到结果
//*[@id="app"]/div/div[2]/div/ul/div[1]/div[2]/p
//*[@id="app"]/div/div[2]/div/ul/div[2]/div[2]/p
//*[@id="app"]/div/div[2]/div/ul/div[3]/div[2]/p
...
# 得到元素
title_e = browser.find_element(By.XPATH, '//*[@id="app"]/div/div[2]/div/ul/div[1]/div[2]/p')
# 获取元素中的“title值”
print(title_e.get_attribute('title'))
得到前10个的名称
for i in range(1,11):
title_e = browser.find_element(By.XPATH, '//*[@id="app"]/div/div[2]/div/ul/div[' + str(i) + ']/div[2]/p')
print(str(i)+":"+title_e.get_attribute('title'))
得到前100个的名称
会得到报错!
原因是当用户没有向下滚动时,下面的数据没有请求和加载
不过我们可以通过JS代码模拟,用户的向下滚动
核心代码:browser.execute_script("window.scrollTo(0, document.body.scrollHeight);")
for i in range(1,101):
title_e = browser.find_element(By.XPATH, '//*[@id="app"]/div/div[2]/div/ul/div[' + str(i) + ']/div[2]/p')
print(str(i)+":"+title_e.get_attribute('title'))
if i%10==0:
browser.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(2)
完整代码
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
browser = webdriver.Edge()
browser.maximize_window()
browser.get('https://www.bilibili.com/')
time.sleep(2)
popular = browser.find_element(By.XPATH, '//*[@id="i_cecream"]/div[2]/div[1]/div[3]/div[1]/a[2]')
popular.click()
time.sleep(2)
handles = browser.window_handles
browser.switch_to.window(handles[-1])
for i in range(1,101):
title_e = browser.find_element(By.XPATH, '//*[@id="app"]/div/div[2]/div/ul/div[' + str(i) + ']/div[2]/p')
print(str(i)+":"+title_e.get_attribute('title'))
if i%10==0:
browser.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(2)
time.sleep(200)
以上简单完成了爬取热门视频的“标题”,还未进入到分析阶段。
